Реферат: Цифровая обработка сигналов (ЦОС) занимает,
как известно, важное место в телекоммуникации, мультимедиа,
радиотехнических системах и других областях. Особенно актуальной она
стала с появлением на рынке высокопроизводительных сигнальных
процессоров (DSP), обеспечивающих реализацию системы на чипе.
Компания SPIRIT Corp. (http://www.spirit.ru/articles/www.spirit.ru
и http://www.spirit.ru/articles/www.spiritdsp.com)
специализируется в области разработки прикладного ПО для подобных
систем, а потому ее опыт, технологии и конечные решения могут быть
интересны широкому кругу читателей журнала.
По договоренности с редакцией специалисты SPIRIT Corp. готовят
ряд статей, охватывающих различные прикладные DSP-задачи (голосовые
технологии, связь, навигация, обработка изображений, компьютерное
зрение и др.). Телекоммуникационная тематика частично была
представлена в # 1, 2003г. в статье, посвященной ПО абонентской
телефонии (CST) для процессора CSTC54 фирмы TI, для которого SPIRIT
Corp. создал соответствующее ПО (50 наиболее популярных телефонных
алгоритмов).
Представленная ниже статья начинает серию статей, посвященных
голосовым технологиям. К ним относятся обработка и редактирование
речи, компрессия речевых сигналов, распознавания и синтез речи,
пометка слов в потоке слитной речи, верификация и идентификация
диктора, речевой морфинг (в частности, модификация голоса), очистка
речи от шумов и искажений, распознавание и коррекция акцента,
распознавание языка, на котором говорит диктор, оценка
эмоционального состояния диктора, синхронизация движения губ в
анимационных задачах и др. SPIRIT Corp. внес свою лепту в разработку
многих из перечисленных технологий и его речевые продукты отвечают
мировому уровню.
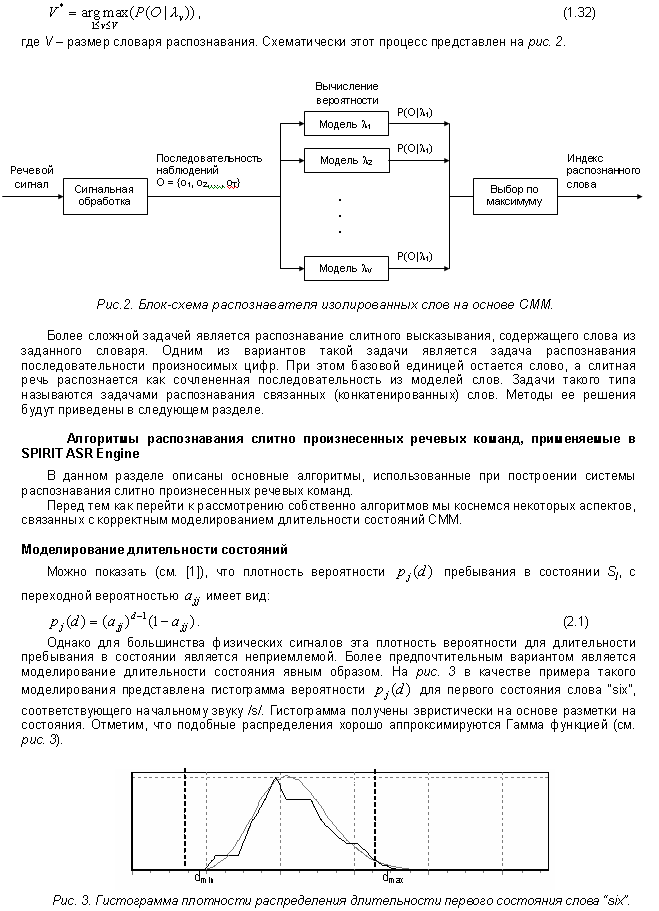
Мы решили начать с автоматического распознавания речи (ASR) и
описать структуру и основные концепции ASR-engine. На ее основе
разработаны распознаватель речевых команд, способный надежно
работать в зашумленной среде, и распознаватель связной речи с
ограниченным словарем. Основой ASR-engine служит собственно
распознаватель, который может быть построен на базе различных
подходов. Наиболее известны скрытые марковские модели (HMM) и
нейронные сети (ANN). В первой статье по ASR освещается широко
используемый метод HMM и его специфика при построении SPIRIT
ASR-engine.
В последующих статьях предполагается рассмотреть и другие аспекты
построения ASR-engine, обеспечивающие устойчивую работу в сложных
акустических условиях.
В зависимости от интересов читателей журнала и обратной связи
будет планироваться тематика последующих статей.
Мы надеемся, что освещение передовых решений в голосовых
технологиях стимулирует деятельность читателей, специализирующихся в
данной области, на повышения качества речевых продуктов и постановку
и решение новых задач.
Введение
Система распознавания речи SPIRIT ASR Engine разработана для
широкого ряда практических задач. К числу таких задач можно отнести,
например, организацию автоматического сall-центра (голосовое
управление системой меню, набор PIN-кода и телефонного номера),
системы безопасности, системы речевого управления и т.д. Система
способна в режиме реального времени производить дикторонезависимое
распознавание цепочек слитно произнесенных слов и отдельных речевых
команд, в том числе и в шумовых условиях при соотношении сигнал-шум
вплоть до +5дБ.
Качество работы системы было протестировано на речевой базе
TIDigits, содержащей цепочки английских цифр от "0" до "9" плюс
"Oh". Общее количество высказываний - 8700 (56 мужчин и 57 женщин)
при длине строки от 1 до 7 цифр. Точность распознавания
изолированных команд (длина строки - 1) составила 99,9%.Точность
распознавания цепочек цифр - 97,9%. При использовании информации о
длине цепочки качество распознавания повышается до 98,8%. Такой
режим используется, например, при вводе PIN-кода или телефонного
номера, когда количество цифр в высказывании известно заранее.
Следует отметить, что алгоритмы системы никак не привязаны к
конкретному языку и составу словаря. При наличии соответствующего
речевого материала система может быть переобучена на любой другой
набор слов и речевых команд, без каких либо затруднений.
В системе SPIRIT ASR Engine были реализованы как известные
решения, такие как Скрытые Марковские модели (СММ), так и
нестандартные подходы, позволившие значительно повысить надежность
распознавания в реальных акустических условиях.
Использование СММ является на сегодняшний день наиболее
популярным и успешно применяемым подходом к проблеме распознавания
речи. В данной статье представлены основные принципы СММ.
В следующей статье будут рассмотрены алгоритмы распознавания
слитно произнесенных цепочек слов, примененные в SPIRIT ASR Engine.
Скрытые Марковские модели
Рассмотрим основные принципы СММ. Более детальное обсуждение
теории СММ и вопросов их применения в распознавании речи можно найти
в [1,2].
Определение Скрытых Марковских моделей
Использование СММ для распознавания речи базируется на следующих
предположениях:
- Речь может быть разбита на сегменты (состояния), внутри
которых речевой сигнал может рассматриваться как стационарный.
Переход между этими состояниями осуществляется мгновенно.
- Вероятность символа наблюдения, порождаемого моделью, зависит
только от текущего состояния модели и не зависит от предыдущих
порожденных символов.
По сути, ни одно из этих двух
предположений не является справедливым для речевого сигнала. Большое
количество исследований было посвящено тому, чтобы сгладить
недостатки этих предположений [3]. Тем не менее, стандартные СММ
являются основой для большинства современных систем распознавания
речи.
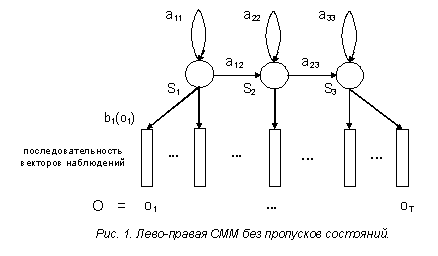
Существует несколько типов СММ, различающихся по своей топологии
(эргодические, лево-правые и др.), с дискретными или непрерывными
символами наблюдения. Для построения данной ASR-engine
использовались лево-правые СММ без пропусков состояний с непрерывной
плотностью наблюдений, именно такие модели и будут рассмотрены. На
рис.1 представлена топология подобной СММ с тремя состояниями.










В следующей статье мы планируем
затронуть проблему устойчивой работы систем распознавания в условиях
зашумленной акустической обстановки. Будут рассмотрены методы и
практические результаты решения этой проблемы.
Литература
- Л.Р. Рабинер, "Скрытые марковские модели и их применение в
избранных приложениях при распознавании речи", ТИИЭР, т. 77, №2,
февраль 1989.
- L.R. Rabiner, B-H Young. Fundamentals of the speech
recognition. Prentice Hall, Englewood Cliffs, NJ, 1993.
- M. Gales, "The Theory of Segmental Hidden Markov Models",
Cambridge University, 1993.